Interactome Analysis
インタラクトーム解析
インタラクトーム (interactome) は、interaction (相互作用) + ome (網羅的な) という語源から作られた造語です。語源の通り、生体内分子間の相互作用を網羅的に解析する研究分野です。
このインタラクトーム解析をバイオインフォマティクスで扱う理由として、次の2つが挙げられます。
- 組合せ数が膨大である
- 経済的に貢献できる
1 つ目の理由に関しては、human は約 23,000 個の遺伝子 (22,205 個の既知遺伝子、2006 年 10 月時点のEnsemble Genome Browser より) を持つといわれていますが、単純にこれらの中から 3 つの組合せを考えただけで、1,000,000,000,000 通りを突破します。これは極端な例ですが、網羅的に組合せ全てを実験的に扱うのは困難であり、バイオインフォマティクスの手法を用いて意義のありそうな候補を抽出することが重要になります。
2 つ目の根拠として、最も身近なバイオ技術の応用先として医薬品が挙げられますが、バイオインフォマティクスを含むゲノミクスの利用で、 新薬開発コスト 800,000,000 ユーロを最大で 305,000,000 ユーロ、平均で 73,000,000 ユーロ削減できるといわれています。
|
インタラクトーム解析の対象としては、
- タンパク質-タンパク質相互作用
- タンパク質-DNA相互作用
- タンパク質-小分子 (リガンド、薬剤、脂質 etc.) 相互作用
などが存在します。
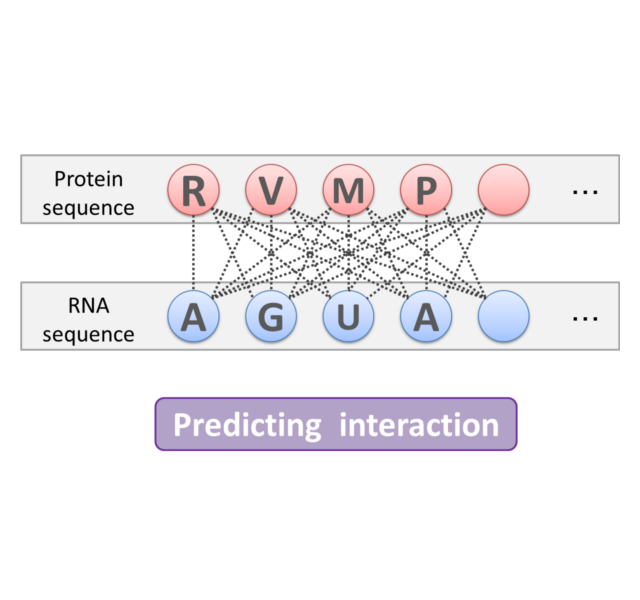
本研究室では、主にタンパク質-小分子相互作用を対象とし、相互作用予測を中心に研究を行っています。
タンパク質-小分子相互作用予測は、タンパク質の特徴と、構造式などの化合物の特徴からこれらの間の関係性を予測することです。膨大な化合物の中から、タンパク質に強く結合し、タンパク質を活性化もしくは不活性化する化合物を発見することは、薬剤開発、ドラッグデザインの初期段階として重要な役割を果たします。
|
この予測を行う具体的な手法としては主に次の 2 つが主流となっています。
- 数理学的・統計的学習手法の利用
- 分子モデリングの利用
当研究室では、主に統計的学習手法を利用しています。これは、これまでに蓄積されてきたデータの中から何らかのルールを見つけ出し、それを新たな予測に利用しようというアプローチです。Support Vector Machine (SVM)等の 2 値識別機械学習手法によって、結合するもの、しないものを分類することで予測を行う試みが広くなされています。バイオインフォマティクスの至上命題ともいえる網羅的予測に非常に適した手法でもあります。本研究室でも、SVM を利用し、様々なタイプの生物学的データを混合した高精度網羅的タンパク質-化合物間相互作用予測手法の開発をテーマに研究が進められています。
インタラクトーム解析はその対象の広さから、まだまだ未着主な部分も多く、製薬などの応用分野に直結していることから、可能性に満ちています。我々は、常に斬新なアイディアで、新たな領域を開拓し、新たな発見をするべく研究を進めています。